


AISA: TAQuant AI Strategy Agent System
Integrating proof-of-concept of agentic QLOB trading
And research models
Technical Research Report
TYLER LEONARD
TA QUANT RESEARCH LABS
January 2026
The TAQuant AI Strategy Agent System
TAQuant Research
Abstract
We introduce the TAQuant AI Strategy Agent (AISA), an autonomous trading system that learns and executes quantitative strategies in real financial markets.
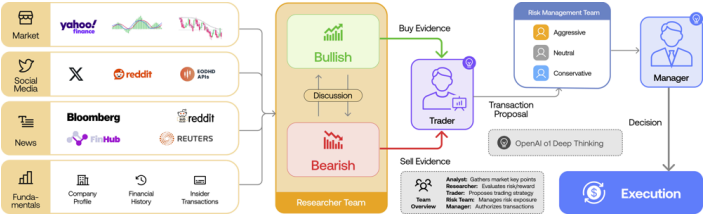
AISA is designed as a capital-executing, policy-learning agent operating within a hedge-fund–grade infrastructure. Its multi-agent architecture partitions trading tasks (e.g. data analysis, strategy evaluation, execution) into specialized components, each with clear responsibilities and interlocks to ensure safety and auditability (see Fig. 1).
The system employs an event-sourced pipeline: all market data and internal signals are logged immutably, enabling offline policy training and full replayability (Appendix B). We integrate a market-regime classifier (Appendix A) to contextualize decisions, and we enforce rigorous governance – including policy versioning, gated approvals, and multi-tier kill-switches – to maintain oversight. Strategy ingestion and adaptation occur offline with delayed updates, while human experts can validate or refine policies (analogous to a “fund manager” role). We also address multi-agent training: competing policy versions are maintained and evaluated, and explainable decision logs allow post-hoc analysis.
This paper details the system architecture, design methodology, evaluation considerations, and discusses limitations and future work, all in the style of a formal quantitative finance research framework.
Introduction
Autonomous agents are increasingly studied for algorithmic trading, but deploying them safely in live markets remains a challenge. Financial markets feature many strategic participants and nonstationary regimes, so single-agent methods can fail to capture market complexity. Multi-agent frameworks attempt to mirror the structure of professional trading desks; for example, TradingAgents and HedgeAgents introduce specialized analyst and trader roles within LLM-powered systems. These systems allocate distinct tasks – sentiment analysis, fundamental research, risk oversight, order execution, etc. – to dedicated agents, often under a central coordinator.
Empirical studies, however, report that even well-designed automated trading systems can underperform in volatile or crisis scenarios (e.g. DeepTrader and FinGPT incurred large losses in rapid market declines). Furthermore, regulators have raised concerns over model governance: in early 2025 the SEC cited a major quantitative fund for failures in oversight and auditability of model changes. Similarly, research has shown that unconstrained reinforcement-learning (RL) agents can converge to implicit collusion or “cartel-like” behaviors without explicit intent. These examples underscore that outcome-only oversight is insufficient.
TAQuant AISA is designed to address these issues. It is a reinforcement-learning–driven trading agent integrated into a robust governance framework. Our contributions include:
(1) an event-driven system architecture that cleanly separates strategy logic, execution, and risk management;
(2) rigorous policy versioning, audit logs, and kill-switch mechanisms;
(3) a taxonomy of market regimes (Appendix A) used to adapt strategies;
(4) a structured workflow for strategy ingestion, delayed offline learning, and human feedback;
(5) support for multi-agent policy competition, policy evolution, and explainable decision logging.
We discuss related work on AI in trading and RL (Section 2), detail the AISA system architecture (Section 3) and methodology (Section 4), and outline evaluation, limitations, and future directions.
Related Work
Reinforcement Learning in Finance
RL and deep learning have been applied to trading and portfolio problems, but traditional RL faces well-known hurdles in finance (nonstationarity, sample inefficiency, and limited interpretability). Recent surveys emphasize that market dynamics are time-varying and require adaptive, regime-aware models. Pure RL agents (e.g. DQN, PPO) can optimize sequences of trades, but may overfit or produce unsafe strategies without domain guidance. Hybrid approaches attempt to combine strengths of different AI: for instance, a recent study uses a large language model (LLM) to propose high-level trading policies that guide an RL executor. Such architectures resemble institutional workflows where strategic insights are generated and then enforced by automated execution (echoing the multiple layers of oversight in a trading desk).
Multi-Agent Trading Systems
Inspiration from human trading firms has led to multi-agent frameworks. TradingAgents, for example, organizes agents into Analysts (fundamental, sentiment, technical), Researchers (bullish/bearish debate), Traders, and Risk Managers. HedgeAgents similarly builds a “well-balanced” set of experts and a fund manager who orchestrates them. These systems leverage agent specialization and structured communication to improve decision quality. Compared to monolithic models, multi-agent designs can naturally enforce separation of concerns and modular updates.
Our AISA follows this paradigm by allocating different decision steps to distinct modules (see Fig. 1). Unlike prior work that focuses on raw trading performance, we emphasize verifiability: we embed logging and oversight at each stage so that all agent actions can be audited.
Governance and Risk Controls
Institutional algorithmic trading must satisfy model risk guidelines (e.g. Fed’s SR 11-7), which require strict version control, validation, and documentation of predictive models. In practice, this means “all predictors, policies, and controllers are versioned, artifacts (code, configs, thresholds) are immutable” and any change is gated through reviews (backtests, stress tests, documentation of data lineage, etc.). Our design aligns with these principles. We employ multi-tier kill-switches and detailed audit trails, logging nanosecond timestamps for every input, decision, and order. This “evidence-first” architecture addresses known failures: e.g., the Two Sigma case in 2025 showed that even with logs, investigators struggled to determine when and how a trading model was altered. By contrast, TAQuant’s event-sourced system (Appendix B) makes the internal decision process independently verifiable.
System Architecture
The TAQuant AISA system follows an event-driven, layered architecture (Figure 1). Incoming market data events (tick prices, order-book updates, news signals, etc.) enter a Signal Processing pipeline that normalizes and enriches information. These events trigger the Strategy Engine which evaluates the current market state under one or more trading policies. Each policy runs in isolation (e.g. in separate containers) to prevent cross-contamination of state. The strategy engine outputs candidate trade signals. Each signal is then sent to the Risk Management layer, which enforces portfolio- and strategy-level constraints (position limits, sector exposures, drawdown bounds, etc.). Signals that violate risk rules are blocked and logged for analysis; approved signals proceed to the Execution Interface.
Figure 1: Exemplary multi-agent trading system architecture. The TAQuant AISA instantiates similar components: data/analysis agents, strategy agents, execution agents, and a risk-management agent.
Approved signals are translated into exchange orders by the Execution Interface. This module chooses order types, venues, and routing strategies, and manages dynamic adjustments (order amendments or cancellations) as market conditions evolve. All actual fills and market reactions are fed back to the system for performance attribution and latency analysis. AISA continuously tracks execution quality (slippage, fill rates, timing) to inform both strategy evaluation and risk monitoring.
Each component is connected by an event log: every market update, internal decision, and order message is timestamped and recorded in an immutable log (see Appendix B). This event-sourced design supports full replayability and auditability. For example, the execution interface will log the exact orders sent, their acknowledgments, and execution details, enabling offline reconstruction of every trade decision and outcome.
The architecture also incorporates a Regime Classification module. AISA classifies the current market regime (e.g. bull, bear, sideways, high volatility, liquidity-crunch, etc.; Appendix A) and tags each event stream accordingly. This contextual label is provided as input to strategy models or policy-selection logic. Internally, regime classification is implemented with ML models (e.g. using PyTorch/MLflow) as part of the strategy infrastructure.
Overall, the design enforces separation of concerns: Strategy logic, Execution mechanics, and Risk controls are kept in distinct layers. This separation (mirroring institutional desks) simplifies testing and auditing of each layer independently. Cross-module interfaces are carefully defined so that, for instance, strategy models cannot place orders directly without passing through risk and execution checks. We also employ containerization and CPU/memory limits to isolate components, preventing a rogue strategy from impairing the system.
Methodology
AISA’s operational workflow is as follows: each trading day, the system ingests live market feeds through the event-driven pipeline, incrementally updating all strategy state. Agents output potential orders in real time, subject to risk gating as described above. Crucially, no new learning happens during live trading. Instead, all market events and decisions are logged and used to train or refine policies offline. This delayed offline learning approach ensures that live capital is never risked on untested policy updates. New model parameters or strategy definitions are only deployed after a validation cycle (see below).
Strategy Ingestion and Human Feedback
New trading strategies (e.g. algorithmic rules or learned policies) enter the system through a controlled “ingestion” process. Strategies may originate from in-house development, external researchers, or even LLM-generated proposals. Each candidate strategy is first verified in a sandbox (backtests and paper trading). After passing automated checks, a strategy can be reviewed by human experts (e.g. a senior quant or portfolio manager). The expert can accept, reject, or suggest modifications, and this feedback is recorded. Thus, human analysts act as a final layer of oversight before a strategy is put into production. Accepted strategies become new policy versions managed by our version control system.
Offline Learning and Policy Updates
Periodically (e.g. nightly or weekly), the collected event logs are used to retrain or update strategy models. For example, an RL agent’s replay buffer is filled with recent trade experiences, and policy/value networks are trained against historical market data. Since all market regimes are represented in the logs (tagged by the regime classifier), training can be stratified or weighted by regime. Performance of new policy versions is evaluated via backtests and forward simulations. Notably, we run multi-agent tournaments: competing policy variants (including historical versions and new candidates) are simulated together in a market model to identify dominant strategies. This competition helps to avoid overfitting to a single market path and to encourage diversity of strategies.
Policy Versioning and Replayability
Every policy version is uniquely tagged and stored (including code, hyperparameters, random seeds). When evaluating or deploying a policy, the exact version can be retrieved. Because the system logs full event histories, any version can be replayed on past market data for analysis. This replayability enables robust testing: for instance, one can simulate how an older version would have acted in a crisis scenario. It also underpins our explainability pipeline: for any trade made in live operation, we can trace back through the logs to produce a rationale. In practice, the system records additional metadata (e.g. key input features or even LLM reasoning snippets) alongside each decision. These serve as an audit trail and as inputs to automated explanations (e.g. “The model bought ABC because strong technical momentum was detected under bullish regime X”).
Multi-Agent Collaboration
Although AISA operates as one integrated system, its internal components can be viewed as “agents” cooperating on the trading task. For example, we implement separate neural modules for signal prediction and for portfolio allocation, which iteratively communicate (in a manner akin to the Researcher–Trader teams of TradingAgents). We also incorporate sentiment or fundamental analysis modules which feed into strategy models. In ongoing work, we experiment with true multi-agent architectures, where multiple policies trade in a shared simulation to model market impact or implied competition. Regardless of the exact agent count, our platform supports structured dialog and data passing among agents: they communicate via shared state objects rather than free-form text, which preserves context and avoids loss of information.
Evaluation Considerations
Evaluating an autonomous trading agent requires both performance and safety analyses. We employ extensive backtesting on historical data, ensuring that test sets include diverse regimes (as listed in Appendix A). Key performance metrics include annualized return, Sharpe/Sortino ratios, maximum drawdown, and tail risk (CVaR) – standard measures in quantitative trading. We also measure execution quality (slippage, fill rates, latency) and risk compliance (how often signals were vetoed by the risk layer). Statistical significance is gauged via bootstrap confidence intervals or block-permutation tests on returns, taking care to avoid lookahead bias.
Importantly, stress scenarios are simulated by isolating extreme market conditions (e.g. flash crashes, low-liquidity periods). We verify that at each of these scenarios, regulatory constraints (e.g. position limits, kill-switch thresholds) would trigger appropriately. Moreover, drift monitors are in place: if a deployed policy’s live behavior deviates significantly from its backtest profile (in terms of selected features or PnL sources), alerts are raised and a retraining cycle is initiated. This live monitoring layer (akin to adversarial testing) complements offline evaluation and is necessary for production readiness.
Limitations
Like all AI-driven trading systems, AISA has inherent limitations. Markets are non-stationary and may shift into regimes not seen in historical training data (e.g. black swan events). Our regime-classification approach mitigates this by detecting shifts, but rapid regime changes can still degrade policy performance. Model risk remains: if input data streams fail or are spoofed, the system could make erroneous trades. While multi-tier kill-switches (per strategy, per asset, or global) provide emergency stops, they cannot prevent all adverse outcomes.
Another concern is emergent behavior: multiple learning agents acting in the same market (or on correlated assets) might collectively produce unintended equilibria. Indeed, prior experiments have observed that independent RL agents can inadvertently collude, stabilizing prices in a way akin to market cartels. Ensuring that AISA’s agents remain competitive yet benign is an ongoing research challenge. Finally, the use of powerful models (LLMs or deep nets) means decisions can be opaque; while we log rationales for each action, true interpretability is limited. Explainability features are heuristic and may not satisfy all regulatory standards. Balancing model complexity with transparency is an inherent trade-off.
Future Work
Future extensions of the TAQuant AISA include richer agent interactions and learning schemes. For example, we plan to explore meta-learning so that the system can adapt more rapidly to new regimes. Incorporating counterparty modeling (simulating how other market participants react) and adversarial testing will improve robustness. We also aim to enhance explainability, perhaps by integrating techniques like SHAP values for model features, or by constraining agents to use interpretable strategies when possible. On the governance side, research into cryptographic audit proofs (as suggested by recent proposals for “verification-first” oversight) could further strengthen trust. As regulations evolve, we will update our compliance modules accordingly (e.g. embedding SR 11-7 documentation directly into the model repository). Finally, real-world trials with careful A/B deployment could validate the system’s effectiveness and illuminate new limitations to address.
Appendix A: Market Regime Classification Taxonomy
We classify market regimes into the following categories to inform strategy behavior. Each regime is characterized by typical price/trend patterns and volatility levels:
- Bull Market (Uptrend): Sustained upward price movements across broad asset classes. Momentum strategies tend to perform well. Low drawdowns; positive sentiment.
- Bear Market (Downtrend): Prolonged downward trends. Mean-reversion and hedging strategies can help. Typically higher volatility and negative autocorrelation in returns.
- Sideways / Range-Bound: Prices oscillate within a bounded range, lacking clear trend. Volatility may be moderate but without directional bias. Oscillator-based strategies often dominate.
- High-Volatility / Turbulent: Rapid price swings and frequent large gaps. Any strategy must manage wide bid-ask spreads and slippage. Risk aversion is key, as drawdowns can spike. (This corresponds to “rapid decline” or “frequent fluctuation” regimes noted in RL studies.)
- Low-Volatility / Calm: Market moves are small and stable. Trend-followers may be side-lined; carry or yield-seeking strategies (e.g. earnings or sentiment plays) may excel.
- Liquidity-Crunch: A regime with thin trading or disrupted order books (e.g. during holidays or exchange outages). Execution risk is high; strategies may throttle participation.
- Event-Driven / News Shock: Regime triggered by specific events (earnings, macro announcements, geopolitical news). Characterized by sudden volatility spikes and regime shifts. Strategies typically pause or switch to news-processing modes.
In Appendix B we describe how AISA detects and logs these regimes. This taxonomy (informed by literature on regime changes) is periodically reviewed and can be refined by unsupervised learning on recent market data.
Appendix B: Event-Sourced Architecture and Learning Boundaries
AISA’s internals follow an event-sourced design: every piece of data (market tick), every agent decision, and every execution outcome is appended to an immutable log. This log effectively becomes the single source of truth for the system’s history. All policy training is done exclusively offline on this logged data. In practice, the live trading process is a consumer of the log (reading data, writing events) but does not itself update model parameters. Instead, learning pipelines read from historical logs to produce new model versions, which are then deployed only after validation.
This separation creates clear learning boundaries: the live capital-facing engine does not self-modify under pressure. New strategies or model updates propagate only via controlled “ship-county” (blue-green) deployments, as in continuous-delivery practices. Because audit trails are cryptographically hashed (via our logging system), any attempt to alter history (e.g. a rogue file edit) would be evident. Audit logs also record the user or process ID for each action, so that questions of “who authorized this trade” can be answered without reliance on human testimony. In sum, by combining event sourcing with strict offline training cycles and multi-layer approval, TAQuant ensures that the system’s behavior is fully reproducible and its learning cannot “leak” unpredictably into live trading.
References
(References correspond to cited works above.)
[8] Xiao et al., TradingAgents: Multi-Agents LLM Financial Trading Framework, arXiv:2412.20138 (2024).
[14] Hoque et al., RL in Financial Decision Making: A Systematic Review, arXiv:2512.10913 (2025).
[18] VeritasChain Standards Org., Audit Trails Are Not Enough: Why AI Trading Needs Verifiability, Medium (2025).
[20] Darmanin & Vella, LLM-Guided RL in Quantitative Trading, FLLM 2025 (preprint).
[22] Darmanin & Vella, Language Model Guided RL in Trading (abstract).
[33] TAQuant Research, TA Quant Technical Whitepaper v1.0 (user file).
[37] T. Green et al., Trading Algorithms in HFT: Governance and Monitoring, IJCTEC 8(5) (2025).
[47] Zhang et al., HedgeAgents: A Multi-Agent Financial Trading System, WWW ’25 Companion (2025).
[43] Hoque et al., RL in Financial Decision Making: Trends & Analysis, arXiv:2512.10913 (2025).
Direct Links
-
[1] [10] [19] [20] ijctece.com
https://ijctece.com/index.php/IJCTEC/article/download/205/167/324 -
[2] [7] [8] Audit Trails Are Not Enough: Why AI Trading Needs Verifiability | by VeritasChain Standards Organization (VSO) | Dec, 2025 | Medium
https://medium.com/@veritaschain/audit-trails-are-not-enough-why-ai-trading-needs-verifiability-8d0c366d2156 -
[3] HedgeAgents: A Balanced-aware Multi-agent Financial Trading System
https://arxiv.org/html/2502.13165v1 -
[4] [5] Reinforcement Learning in Financial Decision Making: A Systematic Review of Performance, Challenges, and Implementation Strategies
https://arxiv.org/html/2512.10913v1 -
[6] [21] TradingAgents: Multi-Agents LLM Financial Trading Framework
https://tradingagents-ai.github.io/ -
[9] [13] [14] [15] [16] [17] [18] Technical Whitepaper [v1.0].md
file://file-FrXATT6yXFK8pzvKXKM7kF -
[11] [12] Language Model Guided Reinforcement Learning in Quantitative Trading Preprint under review for FLLM 2025.
https://arxiv.org/html/2508.02366v1